
AI & Data Science Projects
I am currently curating this list. Please find my GitHub and GitLab projects at:
GitLab Projects →
GitHub Projects →
Explainable RAG
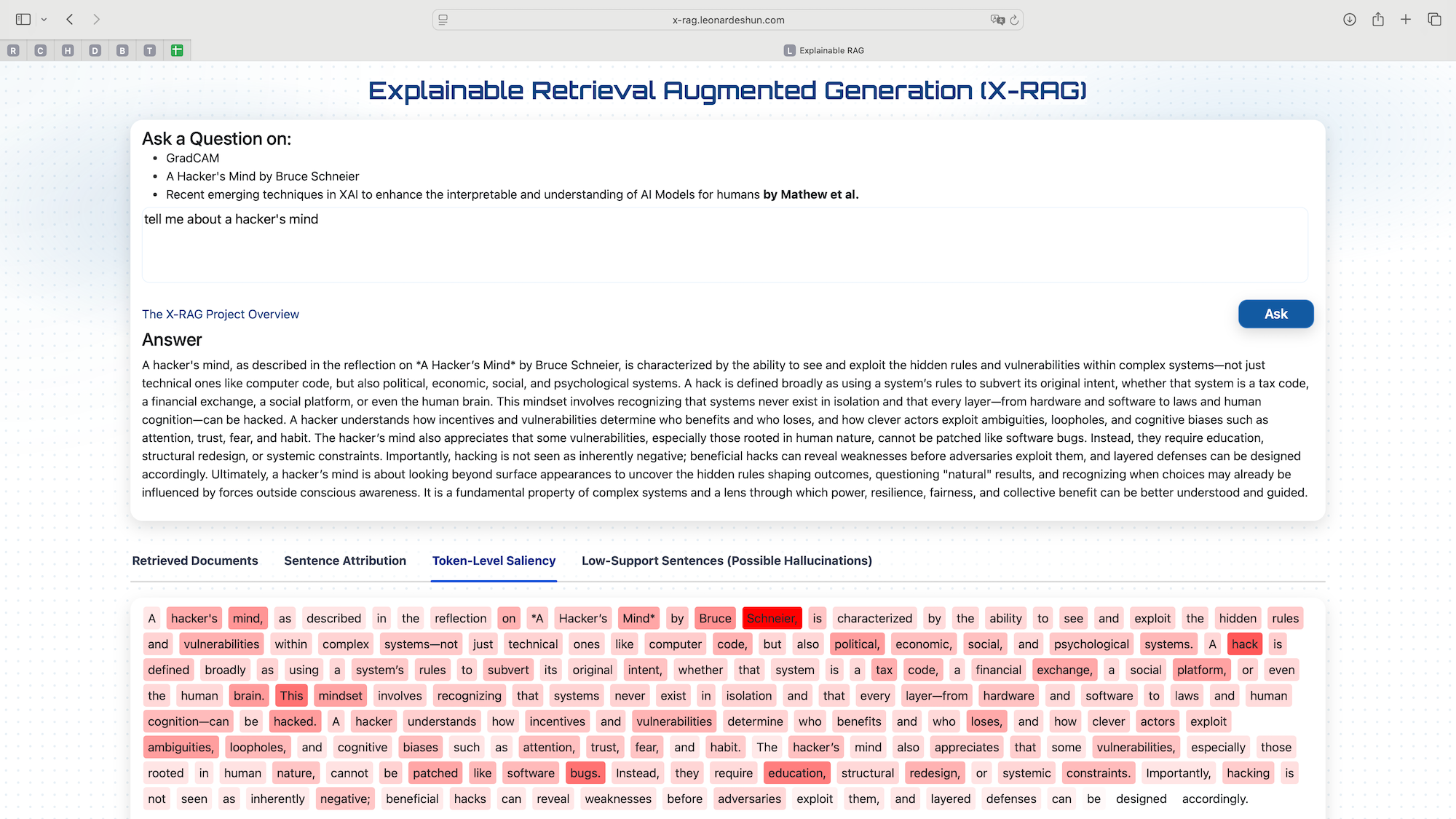
RAG systems use retrieved documents for context but don't tell how each retrieved document chunk affects their responses, so users can't verify faithfulness. Using a RAG system with controlled sources, this project asks the Generation LLM to use only the retrieved context for its response, allowing us to evaluate how the LLMs use the context they get to provide a response.
This was deployed on Google's Cloud Run. Using 4 documents, it retrieves top-3 chunks using Facebook AI Similarity Search (FAISS) vector "database". Embeddings were created with all-MiniLM-L6-v2 from sentence-transformers (HuggingFace). Generation with OpenAI's gpt-4.1-mini and attributing sentences by matching them to their sources (cosine similarity). Computation of token-level saliency (E5 embeddings) was done to show level of reliance on the source and flagging low-support sentences for hallucination detection.
An external Redis from redis.com was used to cache the responses since the GCP instance is ephemeral and the system was dockerized.
Explainable Deep Learning
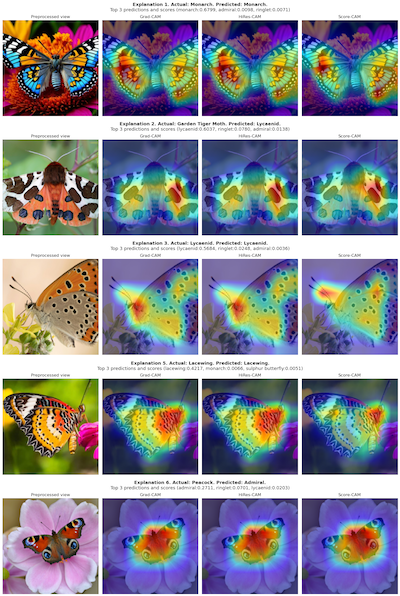
This project uses PyTorch to demonstrate the application of various explainability techniques on a pre-trained ResNet-50 model using butterfly images. It helps to understand how Grad-CAM explainability techniques can be applied to deep learning models.
In this case, the ResNet-50 Classifier is used to classify images of butterflies, and the explainability techniques help to visualize which parts of the images are most important for the model's predictions.
It also highlights the importance of model explainability, and can help us identify potential areas for improvement. It can assist us in the event that we want to retrain the model, to give it effective images, knowing what it attends to, or use a different architecture that may be better suited for distinguishing between similar species.
A RAG Application using LangGraph
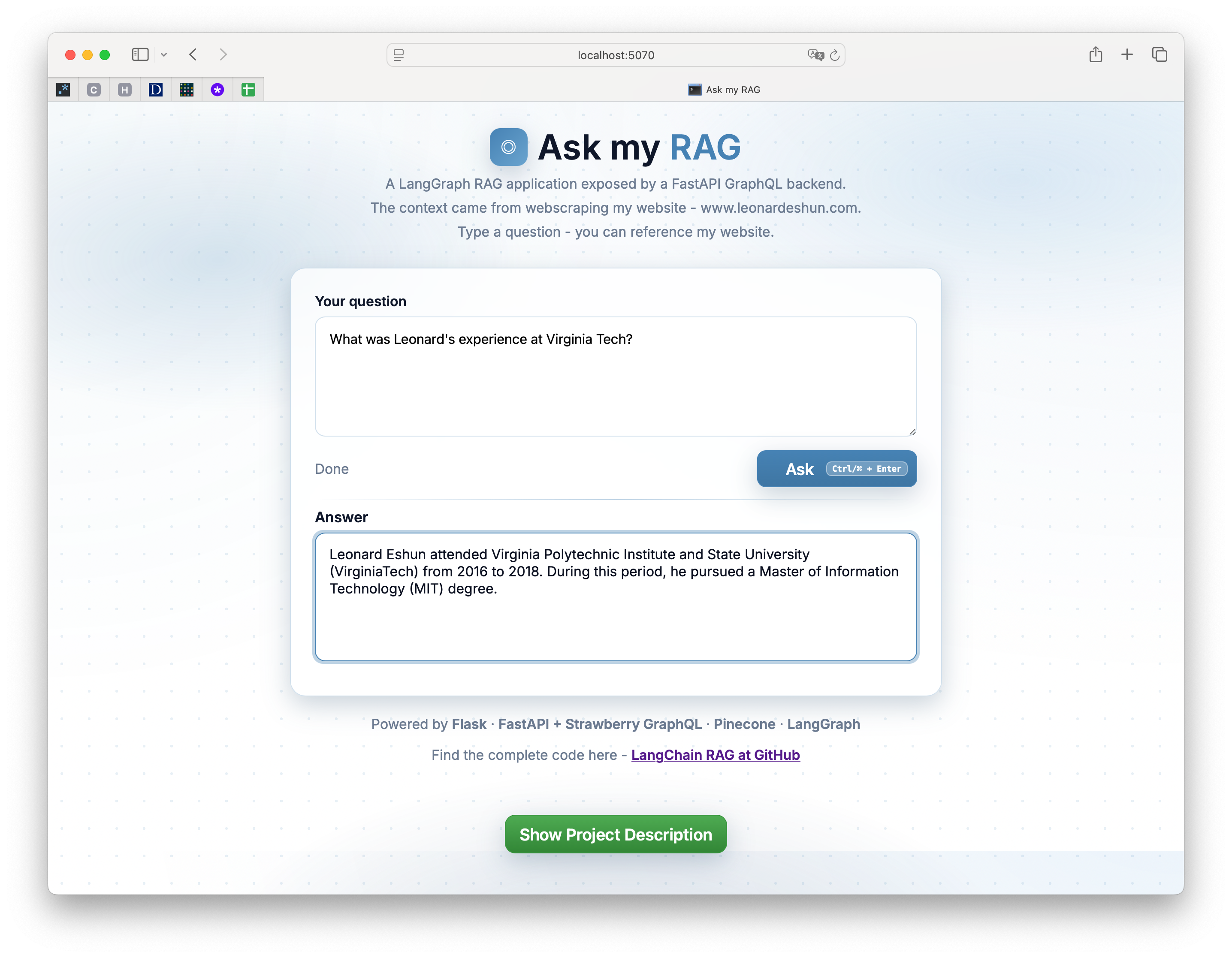
This project demonstrates a LangGraph pipeline served with FastAPI + Strawberry GraphQL, integrated with vector search in Pinecone. A crawler scans my website to collect all accessible links, and the contents are loaded and chunked for efficient processing by the models. Embeddings are then generated from these chunks and stored in Pinecone for later retrieval.
When a user enters a question in the Flask frontend, it is sent to the FastAPI GraphQL backend, which triggers the execution of the LangGraph pipeline. An embedding is created from the question, and a similarity search is performed in Pinecone to find semantically related text. This context is combined with the question to form a prompt for Google's Gemini Flash chat model. The answer is returned through the same pipeline and displayed to the user.
The RAG application is designed to be adaptable: it can work with any website by changing the target domain in the GitHub code, and it can be extended to other data sources by modifying the loader.
Integration of LLM into an application
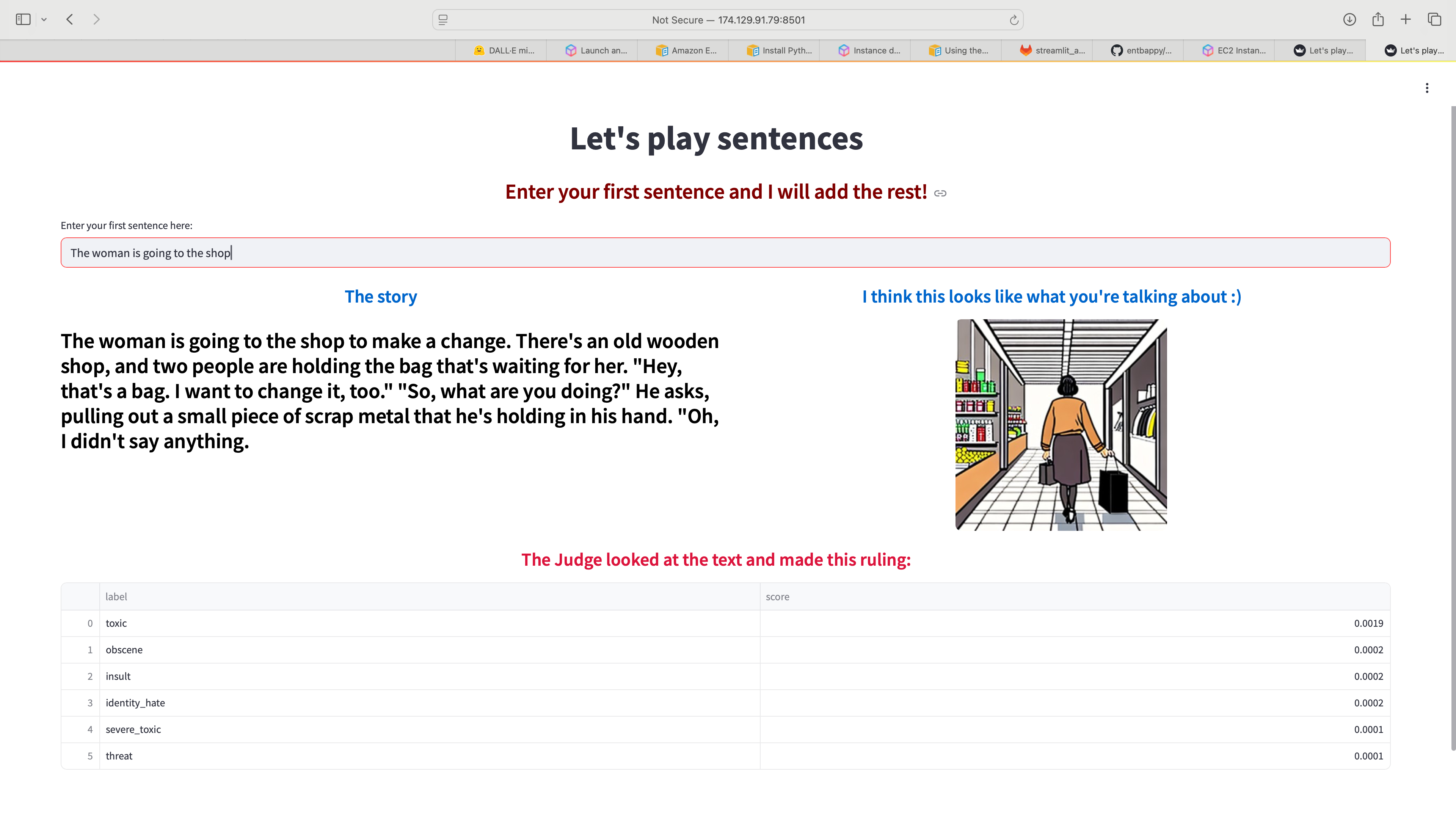
I used Python and Streamlit to create a web application that connects to OpenAI's GPT2, hosted on Hugging Face to complete a sentence. It then uses SD-Turbo to generate a related image and Toxic-BERT to check for inappropriate content generation by the LLM. GitHub CI/CD was used to push the code to an AWS EC2 instance hosting the application.
Text Search with Vector Databases
Written in Rust and containerized with Docker using the Amazon Linux 2023 base image during the CI/CD process in GitLab. The image was pushed to Amazon Elastic Container Registry and used to create a Lambda function with an API gateway to serve the search function. Its main function is to connect to a Qdrant vector database and do a vector search using the text provided to the API. It returns records containing semantically similar words.
The vector database was populated with information on movies from a JSONL file, and the embeddings were created with Cohere’s Embed API.